Aggiungiamo un bel sommario prima di ogni altra cosa, perché il test si sta dilungando molto nel tempo e nei vari passaggi e diventa utile poter saltare in avanti per chi ha seguito dall’inizio.
Le premesse che hanno portato al test
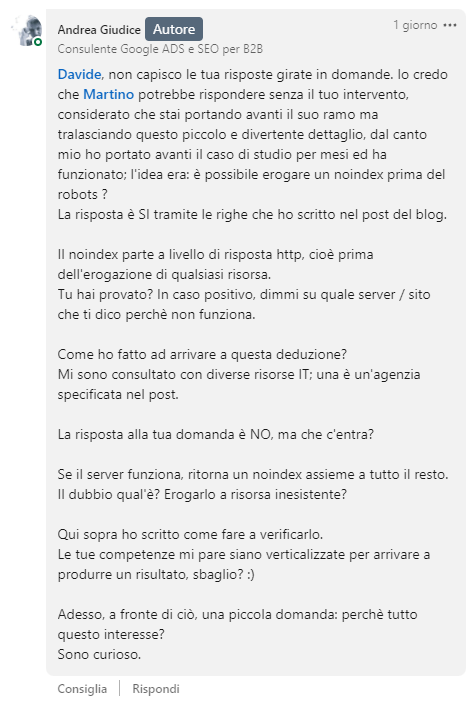
In questi giorni mi è capitato di leggere questo articolo di Andrea Giudice, che tra le varie cose sostiene che il motore di ricerca possa leggere un’istruzione X-Robots-Tag presente negli header di una risorsa, anche in presenza di un’istruzione Disallow nel file robots.txt:
Dall’articolo “Il noindex nell’x-robots-tag fa la differenza”
[…]
Se esistesse il modo di fare leggere il noindex PRIMA del disallow deindicizzeremmo il contenuto dalla serp ed eviteremmo la Scansione.
Ricordiamo anche un’altra faccenda molto importante: il noindex non evita la Scansione della risorsa.
Con il noindex la pagina sarà sempre sottoposta alla Scansione dello spider anche se non apparirà tra le serp, quindi, non otterremo alcun risparmio di crawl budget (motivo per cui fare SEO su Shopify è quasi impossibile perchè non si può editare il robots.txt).
Soluzione: NOINDEX prima di DISALLOW
L’X-Robots-Tag noindex può essere utilizzato come risposta di intestazione HTTP in un determinato URL aggiungendo queste due righe nell’httaccess:
SetEnvIf Request_URI “/pagina/” NOINDEX
Header set X-Robots-Tag “noindex” env=REDIRECT_NOINDEX
Poi, da robots.txt metteremo il disallow:
disallow: /pagina/
Come risultato otterremo che le pagine saranno deindicizzate durante la risposta HTTP tramite x-robots-tag tipo noindex e lo spider non farà la scansione su di esse per via della presenza del disallow nel robots.txt
In pratica, avremo rimosso i contenuti per sempre dalle serp e risparmiato crawl budget.
Ora, diciamolo chiaro: questa cosa non può succedere.
E la ragione è molto semplice… Googlebot per leggere l’istruzione X-Robots-Tag negli header di una risorsa, deve effettuare una scansione. Ma se è bloccato da robots non scansiona e non legge proprio nulla.
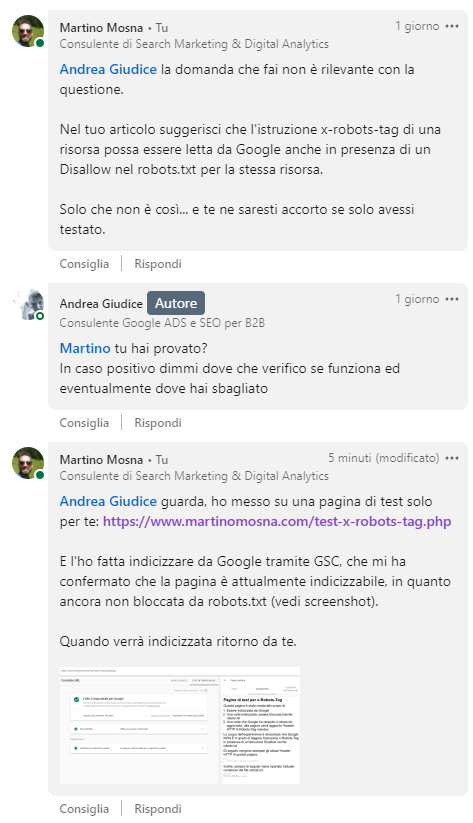
Ho fatto questa mia osservazione ad Andrea su Linkedin, da cui ne è scaturita una conversazione con dei punti di disaccordo, che riporto integralmente:
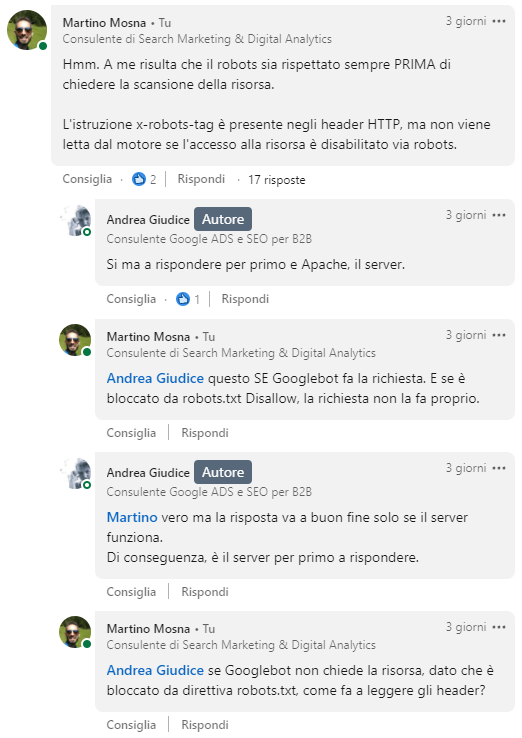
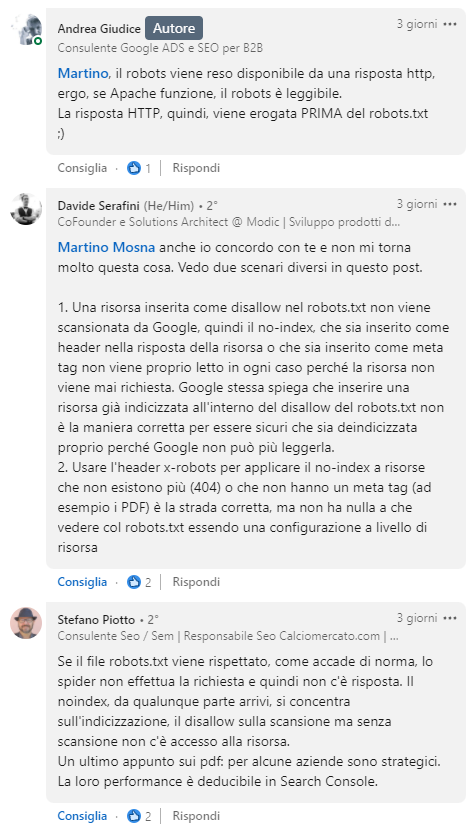
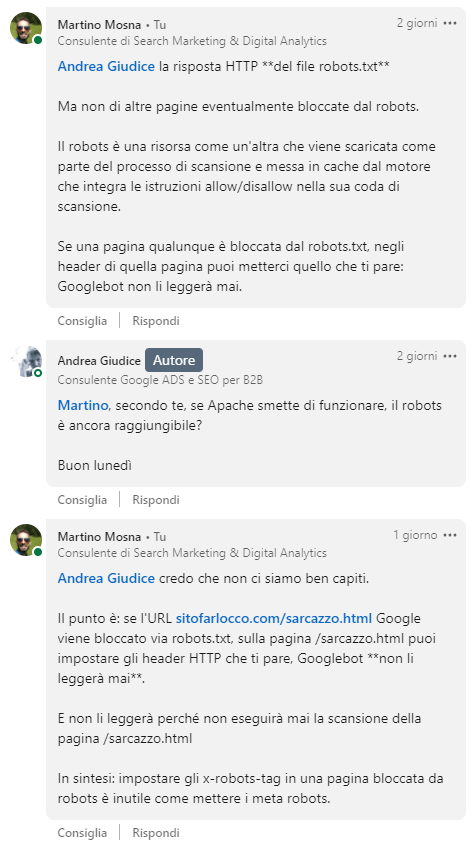
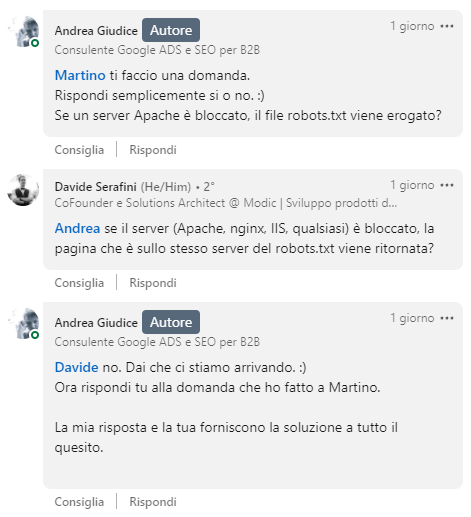
Ed eccoci qua.
Ho creato una pagina per fare il test e mostrare ad Andrea e ad altri che ancora avessero qualche dubbio che Googlebot non è in grado di leggere l’istruzione X-Robots-Tag se bloccato da robots.txt.
Aggiornerò questo post con i vari passaggi dell’esperimento.
04/11/2021
Creazione della pagina e richiesta di indicizzazione
Ho creato la pagina con un brutale PHP e codice HTML scritto a manella.
Per la massima trasparenza, ecco il codice che ho usato:
<?php
//header("X-Robots-Tag: noindex", true);
//Preparo già commentata l'istruzione X-Robots-Tag per quando mi servirà
?>
<html>
<head>
<title>Pagina di test per x-Robots-Tag | Martino Mosna</title>
<meta name="Description" content="Lo scopo dell'esperimento è dimostrare che Google NON È in grado di leggere l'istruzione x-Robots-Tag in presenza di un Disallow nel file robots.txt.">
</head>
<body>
<h1>Pagina di test per x-Robots-Tag</h1>
<p>Questa pagina è stata creata allo scopo di:</p>
<ol>
<li>Essere indicizzata da Google</li>
<li>Una volta indicizzata, essere bloccata tramite robots.txt</li>
<li>Una volta che Google ha recepito il robots.txt aggiornato, alla pagina verrà aggiunto l'header HTTP X-Robots-Tag noindex</li>
</ol>
<p>Lo scopo dell'esperimento è dimostrare che Google NON È in grado di leggere l'istruzione x-Robots-Tag in presenza di un'istruzione Disallow nel file robots.txt</p>
<p>Di seguito vengono stampati gli attuali Header HTTP di questa pagina impostati via PHP:</p>
<pre>
<?php
print_r(apache_response_headers());
?>
</pre>
<p>L'istruzione X-Robots-Tag è visibile utilizzando il pannello Network degli strumenti per sviluppatori del browser (F12)</p>
<p>Inoltre, sempre di seguito viene riportato l'attuale contenuto del file robots.txt:</p>
<pre>
<?php
$file = file_get_contents('robots.txt');
echo $file;
?>
</pre>
</body>
</html>
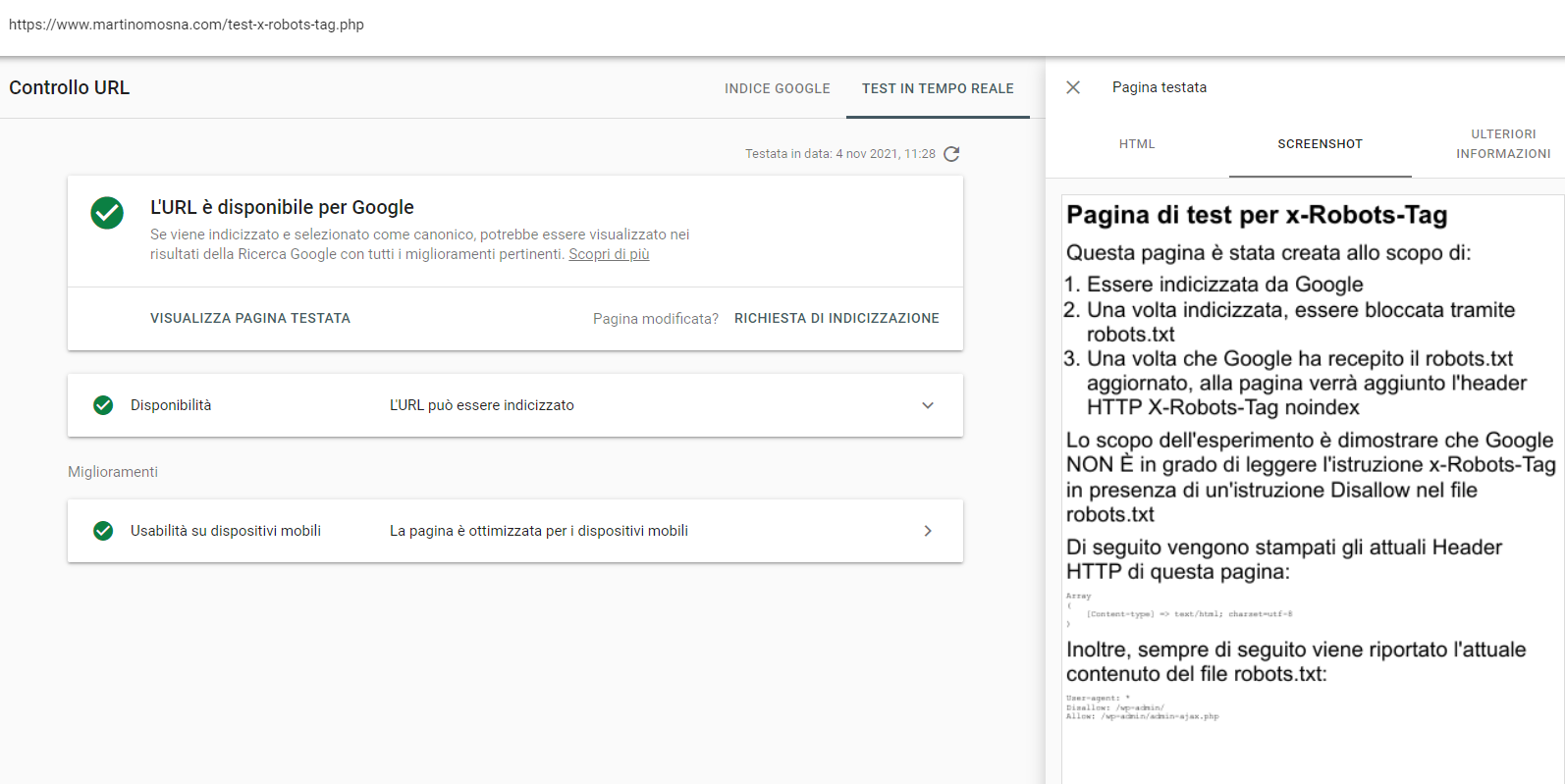
Ho quindi fatto la richiesta di indicizzazione a Google tramite Google Search Console:

E lo strumento di test mi conferma che la pagina è indicizzabile senza alcun problema:
E ora… si aspetta che Googlebot faccia i suoi comodi.
Restate sintonizzati per aggiornamenti!
Aggiornamenti della conversazione su Linkedin
Aggiungo anche questo scambio di pareri abbastanza surreale che ho fatto sempre con Andrea su Linkedin…

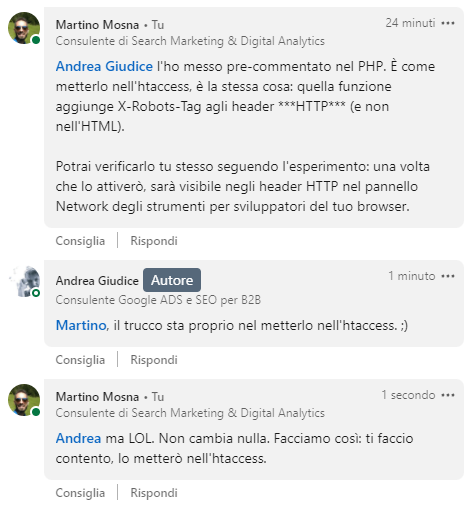
Per quanto lato client (e quindi lato Googlebot che agisce come un client) non faccia alcuna differenza inserire un header HTTP via codice PHP, piuttosto che inserirlo via htaccess… farò un’eccezione per amore di buona fede ed inserirò l’istruzione X-Robots-Tag negli header HTTP tramite htaccess come richiesto da Andrea.
Unico dettaglio: non condividerò il contenuto completo del mio file htaccess per ragioni di sicurezza. Nel file htaccess di questo sito infatti ho inserito diverse righe custom per bloccare alcune tipologie di accesso indesiderato da parte di bot malevoli. Confido nella comprensione dei lettori.
08/11/2021
Sto ancora aspettando l’indicizzazione…
Google è diventato veramente lento ad indicizzare. Sembra di essere tornati negli anni 2000 quando ci voleva una settimana buona per portare la roba su Google. Vabbè, rant veloce e si aspetta.
10/11/2021
E si va di indexing API…
Grazie ad un post di Antonio Mattiacci scopro che Rank Math offre un nuovo plugin che permette di inviare le URL tramite indexing API direttamente da backend di WordPress.
È un plugin standalone, ma ho colto l’occasione per cestinare Yoast e migrare il mio plugin SEO direttamente in blocco a Rank Math, che era un po’ che volevo farlo ed avevo bisogno dell’occasione giusta.
Fra parentesi: mi pare che Rank Math faccia di base le stesse cose di Yoast, ma con (molte) più opzioni di configurazione. Una cosa buona, se sai quello che stai facendo.
Ciancie SEO a parte, ho mandato la richiesta di indexing via API… vediamo come va.
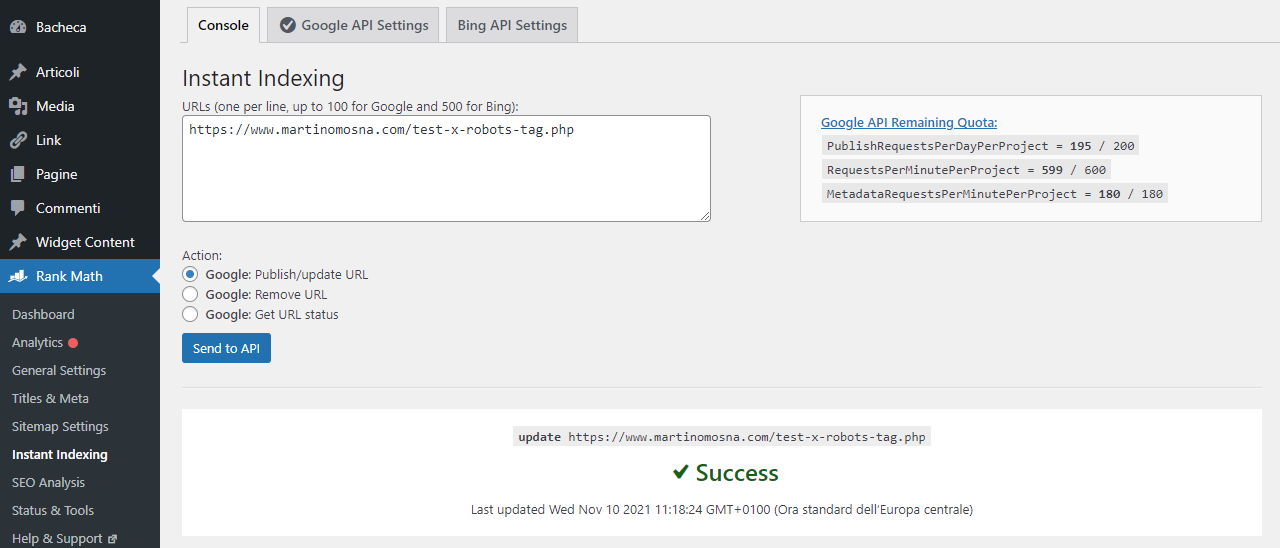
12/11/2021
Niente di nuovo sul fronte Google
Davvero, Google: vuoi svegliarti? Che ci vuole ad indicizzare due URL oggi come oggi? In compenso dopo averlo inviato tramite le sue indexing API, Bing ha indicizzato l’articolo:
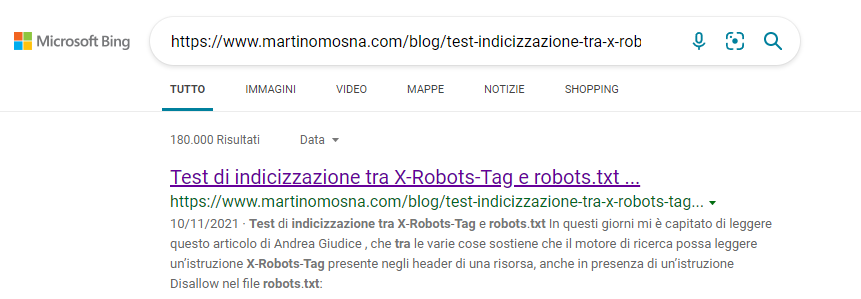
Per la pagina di test ancora non s’è mosso nulla. È pur vero che è molto tempo che non aggiorno questo sito, ma diamine: una settimana per indicizzare mi sembra davvero tantissimo.
20/11/2021
Finalmente Google ha indicizzato!
Devo aver scelto proprio il momento sbagliato per fare il mio test. Per fortuna Google, una volta finito il rollout dell’ultimo Core Update, ha ripristinato le risorse di scansione.
E finalmente siamo indicizzati:

Cambiamo il robots.txt
Per proseguire con l’esperimento, ora bloccherò la pagina di test via robots.txt aggiungendo la riga:
Disallow: /test-x-robots-tag.phpUna volta che Google avrà cachato la nuova versione del robots (e presumibilmente la pagina di test finirà senza titolo e descrizione in SERP), passeremo all’ultima fase, ovvero l’applicazione della direttiva X-Robots-Tag noindex negli header HTTP.
22/11/2021
Robots.txt ancora non cachato
Per il momento Google mostra ancora la versione dello scorso 26 ottobre.
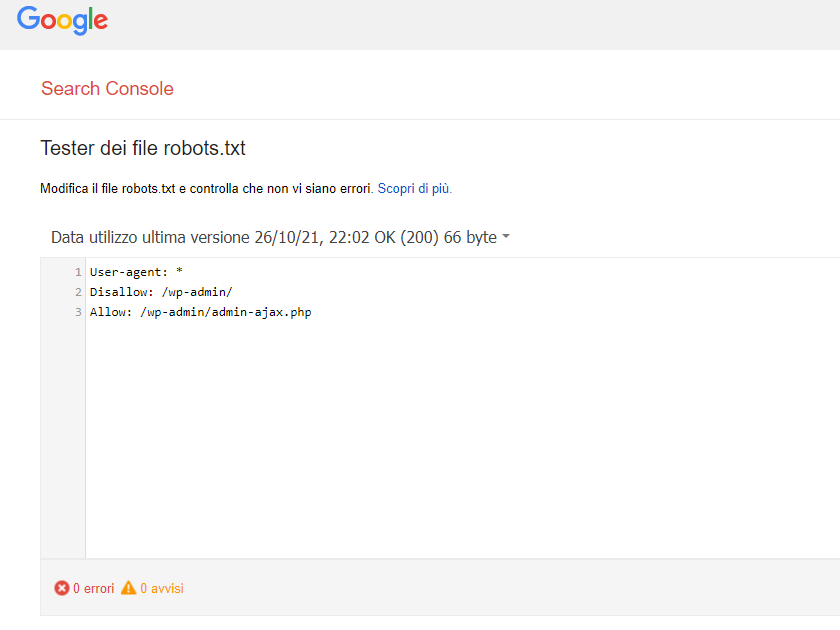
Restiamo in attesa.
Robots.txt recepito da Google
Stavolta per fortuna l’attesa è stata breve: già in mattinata Google ha correttamente recepito il nuovo robots.txt:
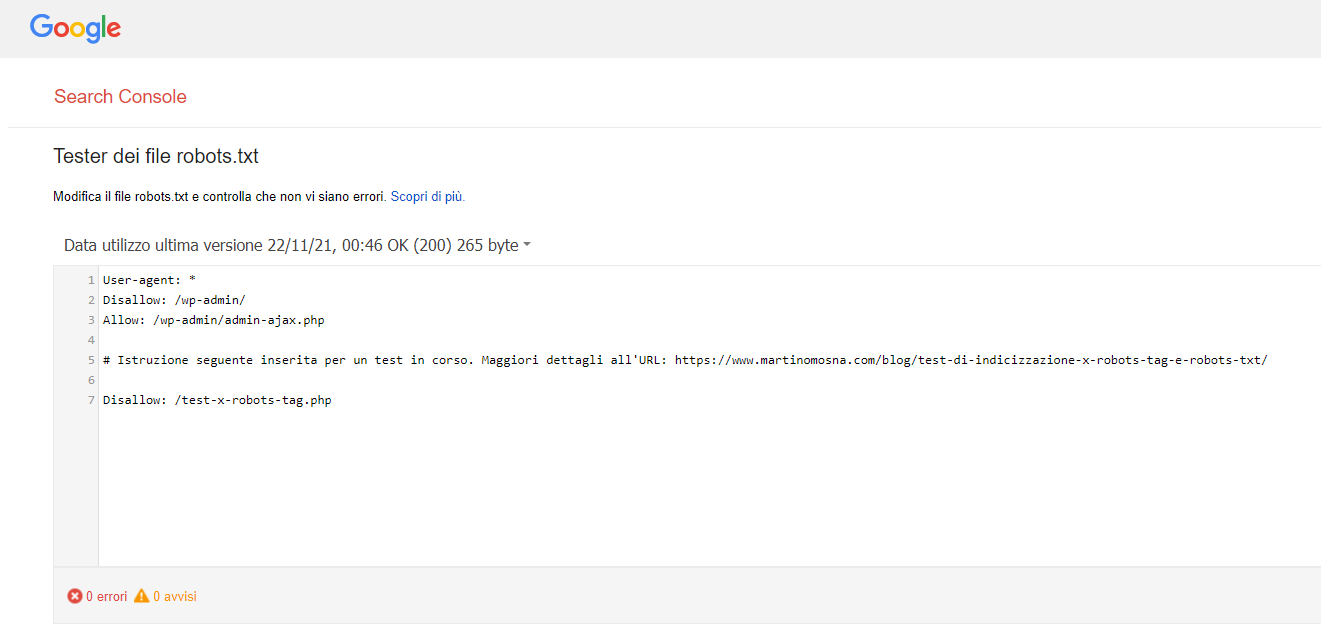
È giunto finalmente il momento dell’ultima parte dell’esperimento, ovvero…
Applichiamo l’istruzione X-Robots-Tag noindex alla URL via .htaccess
Mi raccomando via .htaccess, non perché serva davvero, ma per fare contento Andrea.
Questo il codice che ho aggiunto al mio file .htaccess:
SetEnvIf Request_URI "/test-x-robots-tag.php" NOINDEX
Header set X-Robots-Tag "noindex" env=NOINDEXFaccio fra parentesi notare che l’istruzione indicata da Andrea nel suo post, ovvero:
SetEnvIf Request_URI "/pagina/" NOINDEX
Header set X-Robots-Tag "noindex" env=REDIRECT_NOINDEXNon funzionava correttamente, questo perché la direttiva env=REDIRECT_NOINDEX è da applicare solo qualora vi sia un’elaborazione precedente della URL (come ad esempio nel caso dello script index.php di WordPress che va poi a generare le pagine con URL Rewrite).
Ad ogni modo, ora l’istruzione X-Robots-Tag è impostata.
Prego notare come gli Header HTTP stampati in PHP sulla pagina di test non contengano l’istruzione X-Robots-Tag:
Array
(
[Content-type] => text/html; charset=utf-8
)Questo perché come detto gli header HTTP sono impostati prima, a livello di webserver (e non a livello di script). Per averne conferma è sufficiente verificare gli header di risposta utilizzando il pannello Network degli strumenti per sviluppatori del browser (F12):
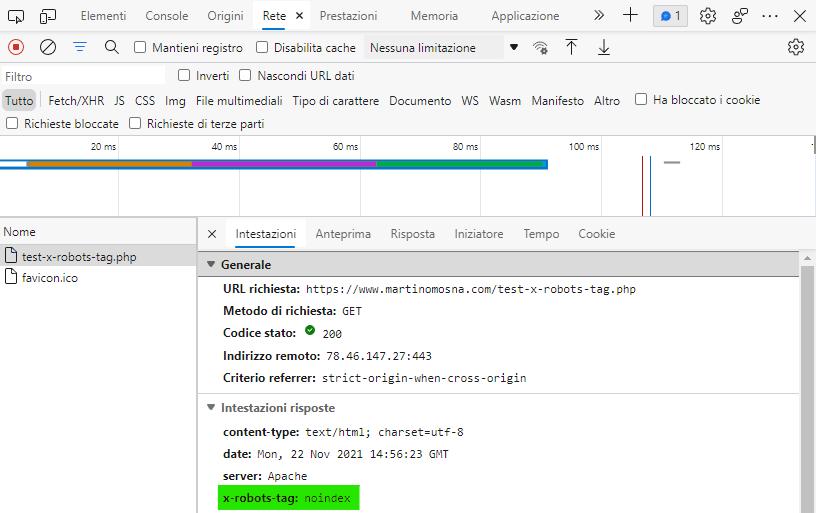
E ora siamo finalmente pronti per l’ultima parte.
Conclusione dell’esperimento
Verifica dell’accesso di Googlebot alla pagina di test
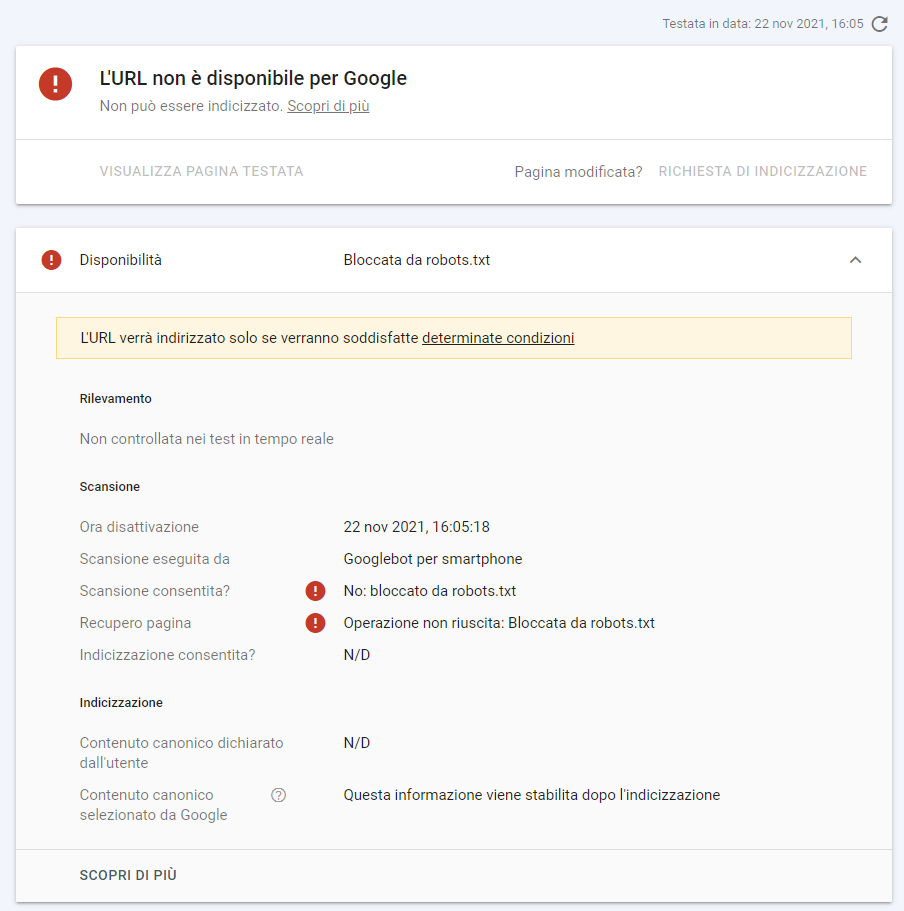
Facciamo innanzi tutto una verifica veloce: Googlebot può accedere alla risorsa? Usiamo lo strumento di test di GSC:

Non ci resta quindi che chiudere la partita…
Richiesta di scansione della pagina tramite GSC
Secondo Andrea, Google dovrebbe leggere l’istruzione X-Robots-Tag e quindi rimuovere la pagina dai risultati di ricerca.
Mentre io sopra scrivevo:
Ora, diciamolo chiaro: questa cosa non può succedere.
E la ragione è molto semplice… Googlebot per leggere l’istruzione X-Robots-Tag negli header di una risorsa, deve effettuare una scansione. Ma se è bloccato da robots non scansiona e non legge proprio nulla.
E ora, rullo di tamburi…
E niente…

25/03/2022
Snippet aggiornata in SERP
Era un po’ che non controllavo, oggi l’ho notato e mi sembrava giusto aggiornare il post: la pagina di test ora risulta indicizzata con la dicitura “Nessuna informazione disponibile per questa pagina. Scopri perché” che Google mette sempre in corrispondenza delle pagine indicizzate a cui non può più accedere in quanto bloccato da robots.txt
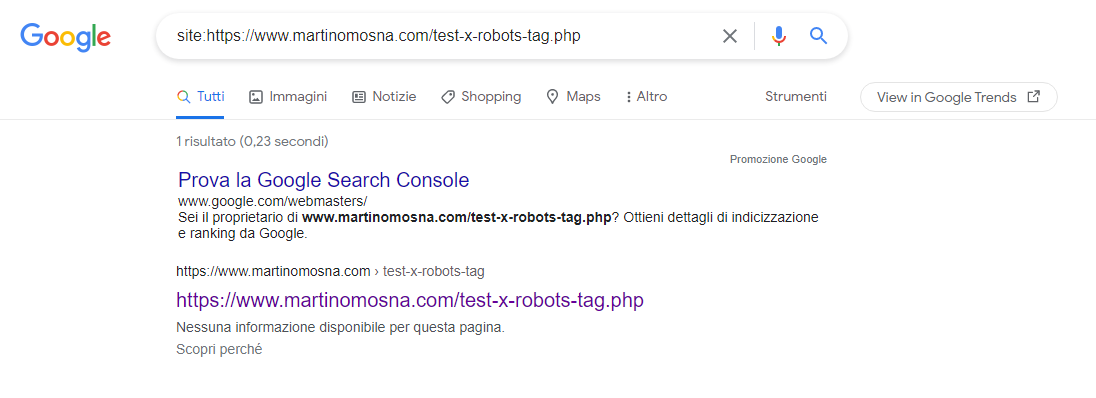
Anche qui, non è nulla di particolarmente sorprendente, ma ci permette di mettere la proverbiale ciliegina sulla torta.
08/07/2022
Pagina non più in SERP
Sono tornato a ricontrollare, perché questo esperimento lo andrò a presentare all’Advanced SEO Tools il prossimo 5 ottobre e volevo assicurarmi di avere tutte le cose in buon ordine.
Salta fuori che la pagina è sparita dalle SERP!
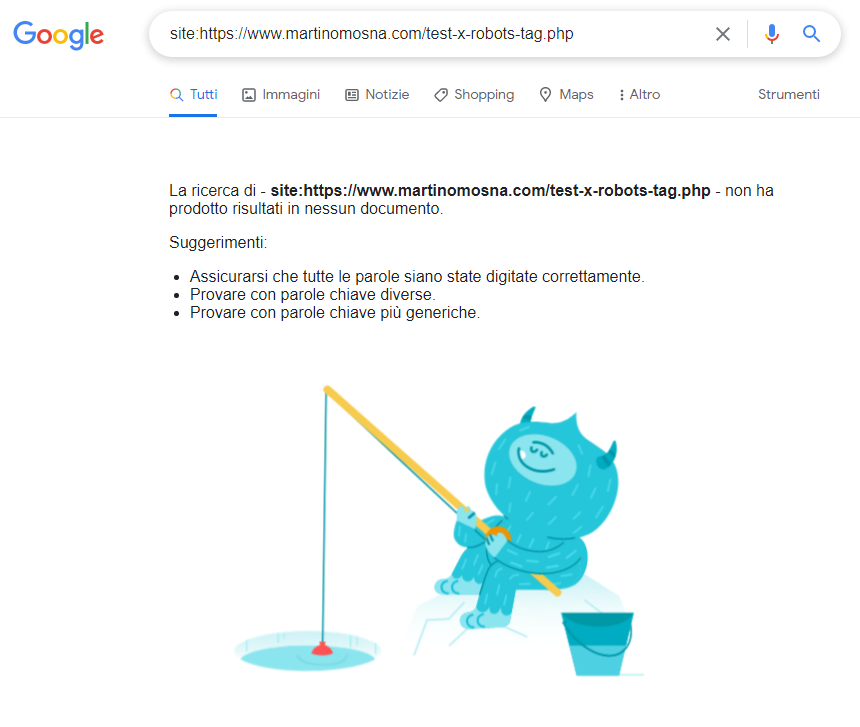
Contrassegnata come indicizzata su Search Console
Google Search Console invece la marca correttamente come “Indicizzata ma bloccata da robots.txt”.
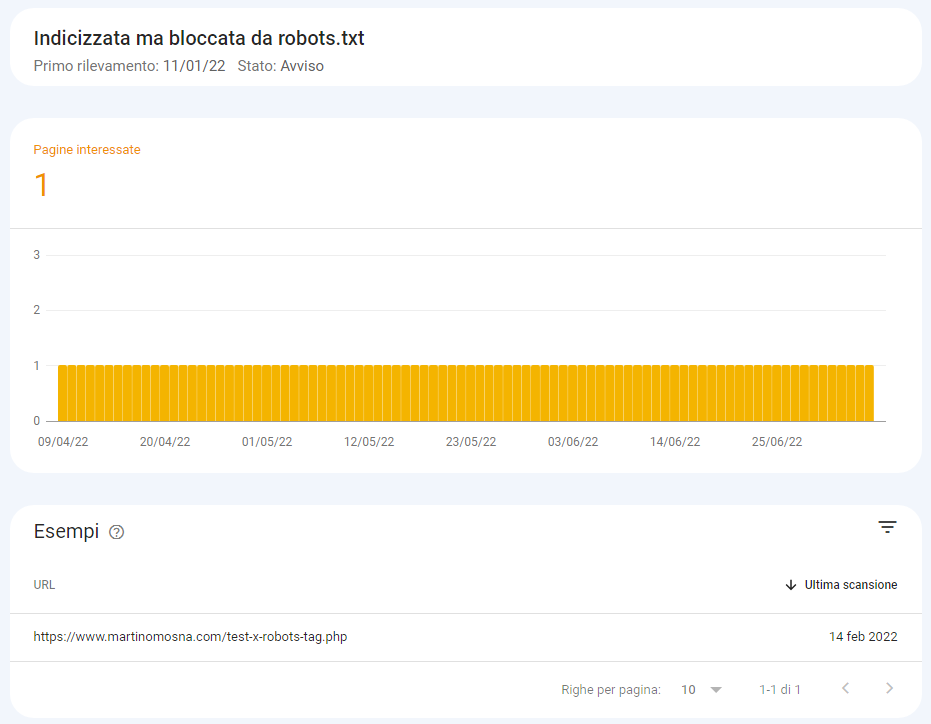
Interessante notare come una pagina possa essere marcata come “indicizzata” su Search Console ma effettivamente non apparire in SERP anche per query estremamente specifiche.
Probabilmente la pagina è comunque marcata in qualche modo come pagina di scarsa qualità (ci sta: è un test che interessa praticamente solo a me) e per questo motivo Google non si prende lo sbattimento di mostrarla in SERP, come faceva con l’apposita dicitura fino al marzo scorso.
Posso solo presumere che quel tipo di risultati venga mantenuto in SERP solo se effettivamente c’è un interesse degli utenti a cliccare comunque quella risorsa.